Summary
- Bruce Schaalje and Paul Fields have published two papers in trade journals for linguistic computing. From the professional end, they improve on the Nearest Shrunken Centroid methods for authorship attribution first employed by Jockers and coworkers, incorporating tests to determine if a closed-set method is appropriate or if open-set methods are required.
- Schaalje and Fields show that their new methods work well for a number of test cases where the methods of Jockers et al. fail. Included among these is a test showing that, when the same closed-set of authors is used as was used to determine supposed Book of Mormon authorship, Sidney Rigdon is shown to have written over half of the Federalist Papers penned by Alexander Hamilton.
- Closed-set methods are misapplied to open-set questions. Next time we will see that the Book of Mormon is an open-set question.
Extended nearest shrunken centroid classification: A new method for open-set authorship attribution of texts of varying sizes
G. Bruce Schaalje and Paul J. Fieldshttp://llc.oxfordjournals.org/content/early/2011/01/18/llc.fqq029.abstract (not free)
Open-Set Nearest Shrunken Centroid Classification
G. Bruce Schaalje and Paul J. Fields
http://www.tandfonline.com/doi/full/10.1080/03610926.2010.529529#.Uv00UbRni2o
Apparently computational linguistics journals work differently from chemistry journals. Studies can take years to get through the queue before publication. These studies, and the 2013 Jockers paper were apparently completed some years before. That said, they are the latest word in peer reviewed journals on Book of Mormon authorship.
I'm going to combine my discussion of these two papers and break it into two parts. The first part will illustrate the failure of a closed-set nearest shrunken centroid (NSC) approach to some known problems, and the success of Schaalje and Fields's open-set modification of these methods. The second part will examine what the open-set modification reveals about Book of Mormon authorship.
How does the open-set NSC work? Basically, start the closed-set analysis. To do this you calculate all of your features for your set of candidate authors and make a set of multidimensional vectors--a bunch of arrows pointing off in different directions. An author can be recognized because all of that author's arrows are approximately the same length and point in approximately the same direction. You also calculate the features for the texts your want to classify in the same way. In the closed-set approach, you measure which author has arrows closest in length and direction to the unknown text and you assign the text to that author. In the open-set approach you look at the arrows before you assign an author. If the arrow from the unknown text isn't close to the arrows of any of the candidate authors then you stop. You say that it looks like an unknown author. Of course the arrow being close to a known author doesn't mean that author wrote it, but if it doesn't agree with any, you need to keep looking.
 |
| Arrows represent the stylometric features vectors of four hypothetical authors |

Since we can't show 150 dimensions on a 2-dimensional plot, some math is done in the background to pick the 2-dimensions that best differentiate among tumor types. These are the 1st and 2nd principle components of the arrows I talked about before. The circles represent the tips of the arrows for tumor types 1-3. You can see that tumor type 4, indicated by +'s, overlaps with the others, so the feature differences aren't big. Despite these similarities, the open-set NSC method classified 95% of the fourth tumor type samples as not belonging to types 1-3. Take a note: that's 95% correctly identified as different compared to 0% by closed-set NSC.
How does open-set NSC do with authorship? A common benchmark for new authorship attribution studies is the Federalist Papers. In my unsystematic foray into authorship attribution, I have found no fewer than 6 new methods tested on the Federalist Papers, and many papers that cite the earliest study on the Federalist Papers by Mosteller and Wallace, and it's not uncommon to find references to a study done by Holmes in the 1990s. The papers by Schaalje and Fields are one of the new methods. Let's see how closed-set and open-set NSC do. I'll summarize. you can find, or I can send you, the papers if you want to see the details.
- All the arrows for the 12 disputed Federalist Papers fall within the range of arrows for Hamilton and Madison, so a closed-set test is appropriate.
- All 12 of the disputed papers were assigned to Madison, in agreement with the majority of previous studies by other methods.
- Pretending that they didn't know who wrote the five papers by Jay, the arrows for those papers don't match up with the arrows for Madison and Hamilton, so the open-set method tells you to go look for another author.
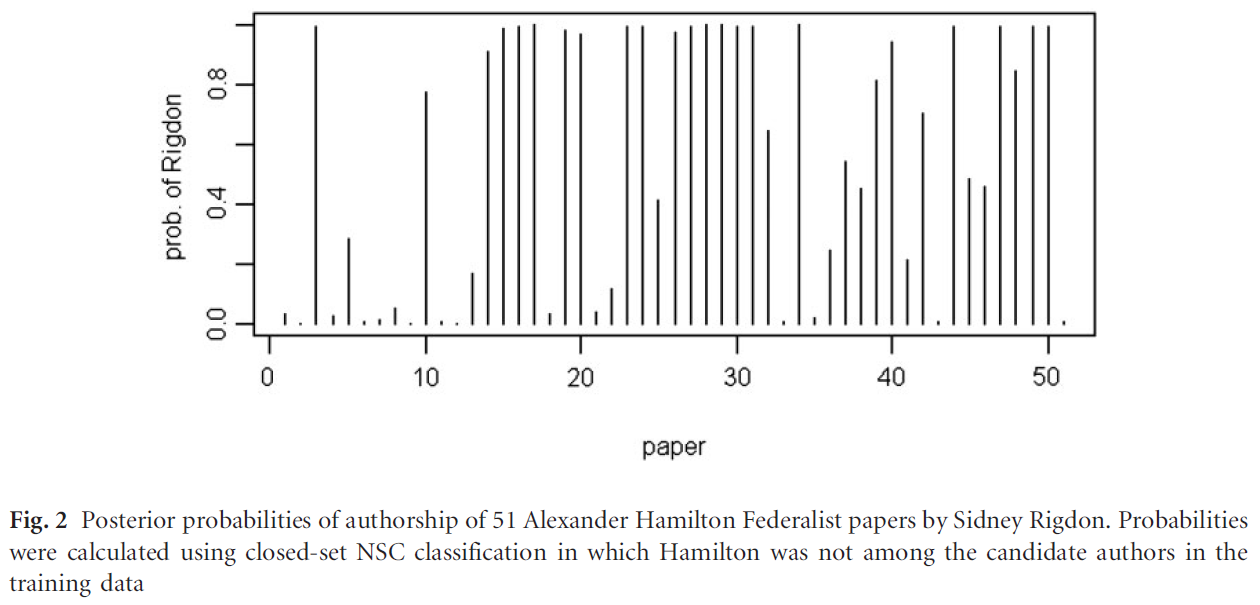
Oops. Looks like Rigdon wrote at least half of them. Let's look at what would have happened if a visual, principle components analysis of the stylometric features had been performed first:


[Technical note: You may have noticed that the values for the training set (candidate authors) shift in each graph. This is not because the values for the stylometric features change (although they may, somewhat, with NSC analysis since the training set has changed), but because the principle components change. I can discuss this with anyone who wants to understand it better.]
As one last technical test, Schaalje and Fields added a further calculation to the model to account for text length. It improved the results on a stylometrically ambiguous data set, but did not solve the problems resulting from small text lengths. What this means for us is that short chapters in the Book of Mormon are more likely to have false positive assignments than longer ones, even with open-set NSC methods.
The take home message is, closed-set NSC can give 100% false positives if the right checks aren't made. Instead of making these statistical checks, Jockers, Witten, and Criddle relied on subjective historical analysis. Next we will see what they would have learned had they made one simple, statistical check, and see what Schaalje and Fields found using open-set NSC methods on the Book of Mormon.
No comments:
Post a Comment